请注意,本文编写于 259 天前,最后修改于 259 天前,其中某些信息可能已经过时。
目录
ChatGPT在做什么?它为何能做到这些?
类人任务(human-like task)的模型
图像识别 一个简单的例子是包括数字的图像(这是机器学习中的一个经典的例子)

简单粗暴的做法
获取每个数字的大量样本图像,要确定输入的图像是否对应于特定的数字,可以逐像素地将其与已有的样本进行比较
人类的做法 作为人类的我们,似乎肯定做得更换; 因为即使数字是手写的,有各种涂抹和扭曲,我们也仍然能够识别它们。
用建模做法 我们将图像中每个像素的灰度值视为变量,存在涉及所有这些变量的函数,能告诉我们图像中是什么数字。 我们将一个图像的像素值集合输入这个函数,那么输出将是一个数,明确支出该图像中是什么数字。
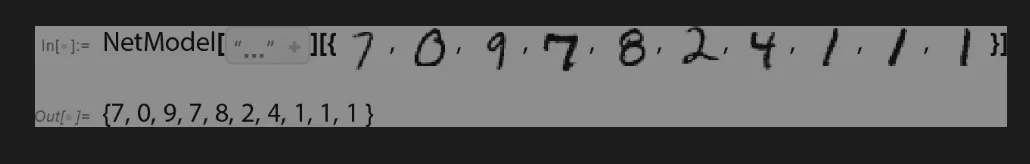
函数识别模糊的数字,开始出现“错误”的结果
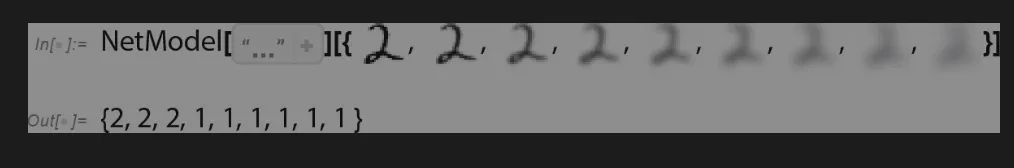
引出问题
面对一个模糊的图像,并且不知道其来源,人类会用什么方式来识别它?
如果函数给出的结果总是与人类的意见相符,那么我们就有一个“好模型”。
能“用数字证明”这些函数有效吗?不能。
神经网络
用于图像识别等任务的典型模型到底是如何工作的呢? --神经网络
本文作者:bob
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录